





Most AI agent demos look impressive for five minutes and painful in production.
They can call a tool, stream a paragraph, maybe update a document, and then stop right where the real engineering work begins. Once you put an agent inside an actual product, you need much more than tool calling. You need resumable state, predictable execution, permission boundaries, observability, retries, approval flows, abort handling, model routing, and a UI that explains what the agent is doing without exposing raw implementation noise.
Here is what breaks when those pieces are missing:
- Tool loops that never terminate
- Writes that cannot be undone
- Streams that say "thinking" but explain nothing useful
- Background runs that fail with no resumable state
- Product teams that cannot answer a simple question: what did the agent actually do?
When we launched agents at our product, we built them too much like model wrappers. Early demos looked good. Production exposed the gaps fast: brittle state, tool loops, weak recovery, and UI flows that held up only as long as users stayed on the happy path.
We have rebuilt the system several times since then. Each pass pushed us toward the same conclusion. An agent is not just a language model with tools bolted on. It is a workflow runtime that uses a language model as one part of the system. Model quality still matters, but reliability comes from the runtime around it.
This post is a condensed version of those rebuilds. It describes the architecture we are seeing that is working well, and the direction we believe product teams should take if they want agents that hold up in production.
The core principle: an agent is a runtime
An AI agent should not be a single function that sends messages to a model.
It should be a runtime with clear responsibilities:
- Maintain conversation and execution state.
- Convert product context into model-readable context.
- Stream model output and lifecycle events.
- Execute tools safely.
- Persist enough information to resume, inspect, undo, and debug runs.
A minimal production interface looks like this:
type AgentRuntimeInput = {
conversationId?: string
userId: string
teamId: string
modelKey: string
systemPrompt: string
messages: AgentMessage[]
tools: AgentTool[]
context: ProductContext
signal?: AbortSignal
}
type AgentRuntimeEvent =
| { type: "agent_start" }
| { type: "turn_start"; turn: number }
| { type: "message_delta"; text: string }
| { type: "tool_start"; toolCallId: string; toolName: string; args: unknown }
| { type: "tool_update"; toolCallId: string; result: unknown }
| { type: "tool_end"; toolCallId: string; result: unknown; isError: boolean }
| { type: "turn_end"; stopReason: string }
| { type: "agent_end" }
| { type: "error"; message: string }The important design choice is not the exact TypeScript. It is the event stream. Your UI, API route, background worker, and persistence layer should all consume the same stream of structured events.
That one decision pays off everywhere. The frontend gets stable states to render. The backend gets deterministic logs. Tests can assert event order. New tools can plug into the system without becoming one-off UI integrations.
The runtime loop is where reliability starts
Most agent failures are not prompt failures. They are runtime failures.
The loop itself is simple:
while (turn < maxTurns) {
emit({ type: "turn_start", turn })
const modelResult = await model.stream({
systemPrompt,
messages: transformContext(messages, context),
tools: toolRegistry.toModelDefinitions(),
signal,
onTextDelta: (text) => emit({ type: "message_delta", text }),
})
if (modelResult.toolCalls.length === 0) {
break
}
const toolResults = await executeToolBatch(modelResult.toolCalls)
messages.push(toAssistantTurn(modelResult))
messages.push(toToolResultTurn(toolResults))
emit({ type: "turn_end", stopReason: modelResult.stopReason })
}What matters is everything around that loop:
- Hard turn limits so broken tool plans do not run forever
- Structured tool results so the model can reason over outcomes instead of vague strings
- Abort propagation so "Stop" in the UI cancels both the model stream and long-running tools
- Fallback finalization so the runtime can recover when a model completes tool work but never produces a user-facing answer
- Retry policy for transient failures such as rate limits, timeouts, or unstable upstream APIs
If your agent can create drafts, mutate records, queue jobs, or call external systems, you do not have a chat loop anymore. You have a workflow engine with a language model inside it.
Tools need policy, not just schemas
In demos, tools are usually treated as plain functions with name, description, and parameters.
That is not enough in production. A tool is a product API with governance attached.
type AgentTool = {
name: string
label: string
description: string
parameters: JsonSchema
executionMode?: "parallel" | "sequential"
riskLevel: "read" | "write" | "external_side_effect"
prepareArgs?: (args: unknown, context: AgentContext) => unknown
beforeExecute?: (input: ToolExecutionInput) => Promise<{
blocked?: boolean
reason?: string
requiresApproval?: boolean
}>
execute: (input: ToolExecutionInput) => Promise<ToolResult>
afterExecute?: (input: ToolExecutionResult) => Promise<ToolExecutionResult>
}This structure gives the runtime enough information to behave like a product, not a demo.
Separate tool planning from tool authority
The model should decide intent. The product should decide authority.
A model can request:
{
"name": "publish",
"args": {
"entityId": "article_123"
}
}The runtime still decides whether that action is allowed.
That check can include:
- User permissions
- Team plan limits
- Workspace settings
- Approval requirements
- Entity ownership
- Risk level
- Quiet hours
- Rate limits
- Whether the agent is in suggest mode or autopilot mode
This is the line that keeps agents safe: the model proposes actions; the runtime authorizes actions.
Decide what can run in parallel
Read-only tools often do not need to block each other. Loading relevant product knowledge and fetching recent GitHub commits can usually run in parallel.
Write paths should usually be sequential. Updating an article, publishing an announcement, capturing a screenshot, and moving a roadmap item should happen in an order you can explain and replay.
Treat undo as a runtime feature
If an agent can write, it should be able to undo.
const snapshot = await snapshotEntity(entity)
const result = await tool.execute({ args, entity, user })
await AiUndoEntry.create({
conversationId,
entityType,
entityId,
action: { toolName, args },
snapshot,
})That turns "undo that" from a prompt gamble into a real product capability.
Context, model routing, and streaming should be first-class layers
Raw message history is not the same thing as model context.
Before every model call, the runtime should transform context into something the model can actually use:
async function transformContext(messages, productContext) {
return [
summarizeOldTurns(messages),
injectCurrentEntity(productContext.entity),
injectRelevantKnowledge(productContext.knowledge),
injectRecentToolResults(messages),
stripUiOnlyMessages(messages),
]
}This is where you prune old turns, inject the currently open entity, include relevant product knowledge, carry forward recent tool outputs, and strip out frontend-only noise.
Without this layer, prompts slowly become a dumping ground. With this layer, you can improve context quality without rewriting the runtime loop.
Route models through product policy
Production systems rarely stay on one model forever. You will want cheaper default models for common work, stronger reasoning models for complex tasks, and fallback behavior when an upstream provider is unavailable.
const MODEL_REGISTRY = {
fast_default: {
provider: "gemini",
label: "Gemini Flash",
maxOutputTokens: 65536,
supportsThinking: true,
},
reasoning: {
provider: "anthropic",
label: "Claude Sonnet",
maxOutputTokens: 64000,
supportsTools: true,
},
}Then resolve the actual model through policy:
const modelKey = resolveModelKey({
requestedModelKey,
agentType,
teamPlan,
teamConfig,
fallbackModelKey,
})This keeps the UI simple while giving the backend room to evolve.
Stream product events, not just text
Streaming is part of the product interface. If the only thing your stream can send is a text delta, your UI has no structured way to explain progress.
Useful streams include lifecycle events like these:
emit({ type: "tool_start", toolName: "fetch_github_commits" })
emit({ type: "tool_end", toolName: "fetch_github_commits", result: { totalCount: 14 } })
emit({ type: "message_delta", text: "I found 14 commits..." })
emit({ type: "tasks_created", tasks })
emit({ type: "undo_entry", undoEntryId })The frontend can convert those into progress steps, generated content cards, inbox tasks, approval prompts, and undo buttons. The key is stability. Once the client starts parsing arbitrary ad hoc events, every new tool becomes a frontend rewrite.
Persistence is what makes agents inspectable and resumable
A production agent should persist much more than the final assistant message.
At minimum, persist:
- Conversation metadata
- User messages
- Assistant messages
- Tool calls
- Tool results
- Undo entries
- Generated entities
- Background task IDs
- Run status
- Error details
- Timing information
This gives you the product behaviors users actually expect:
- Reopen an old conversation
- Inspect what the agent did
- Resume failed work
- Show generated drafts
- Undo destructive changes
- Audit scheduled or automated runs
- Debug failures after deployment
For background agents, it is useful to persist runs separately from chat transcripts:
type AgentRun = {
teamId: string
agentType: "workspace" | "release" | "help_center" | "voc"
triggerSource: "manual" | "schedule" | "webhook"
status: "success" | "error" | "skipped"
signalIds: string[]
proposalsCreated: number
reasoningTrace: unknown
error?: string
startedAt: Date
finishedAt: Date
}Interactive chat and background automation should share the same runtime where possible. The trigger changes. The execution model should not.
Observability and validation are runtime features
Teams usually discover this too late: if you cannot see what the agent did and verify whether it did the right thing, you do not have a reliable system.
Observability starts with the same event stream and persistence model the rest of the runtime uses. Every meaningful step in a run should be traceable:
- Which model was called
- Which tool was requested
- Which tool actually executed
- Whether approval was required
- How long each step took
- What state changed
- Why the run ended in success, error, or partial completion
That is what lets product teams answer the questions that show up in production: Why did this draft get created? Why did this run stop? Why did the agent skip publish and ask for approval instead?
Validation matters just as much. It should happen at multiple layers:
- Input validation before a tool runs, so malformed arguments never reach your product APIs
- Policy validation before a write happens, so permissions, workspace rules, and operating mode are enforced consistently
- State validation before mutation, so the runtime checks that the target entity exists and is still in a valid state for the requested action
- Outcome validation after execution, so the runtime verifies that the side effect actually happened and produced the expected result
Without that last layer, agents can fail in the most dangerous way: they appear successful while leaving the product in the wrong state.
This is also why observability and validation should live in the runtime, not inside individual prompts. Prompts can suggest what should happen. The runtime is what proves what actually happened.
Add explicit operating modes
Human approval should not be bolted on later. It should be part of the runtime contract from the start.
type AgentMode =
| "off"
| "suggest"
| "auto_notify"
| "auto_silent"In suggest mode, the agent creates proposals and a human approves them.
In auto_notify, the agent can execute low-risk approved classes of actions and notify the team.
In auto_silent, the agent can perform low-risk work without interrupting users.
The important point is that the same tool can behave differently depending on the mode. generate_article may create drafts automatically. publish may still require explicit approval unless the workspace configuration allows it.
Test the runtime, not just the prompt
The fastest way to build fragile agents is to test them only by talking to real models.
Use fake providers that return deterministic responses:
fakeModel.setResponses([
assistantMessage([
text("I'll fetch recent commits."),
toolCall("fetch_github_commits", { repo: "acme/app", days: 7 }),
]),
assistantMessage("I found 14 commits and created a draft changelog."),
])Then test the runtime itself:
- Events are emitted in the correct order
- Tool args are validated before execution
- Tool calls and results are persisted
- Tool errors are surfaced cleanly
- Max turn limits are respected
- Abort signals cancel the run
- Undo entries are created for writes
- Blocked tools are not executed
- Saved context can resume a run
This is where reliability actually comes from. Prompt quality matters, but runtime tests are what keep the system stable when products, tools, and model providers change underneath you.
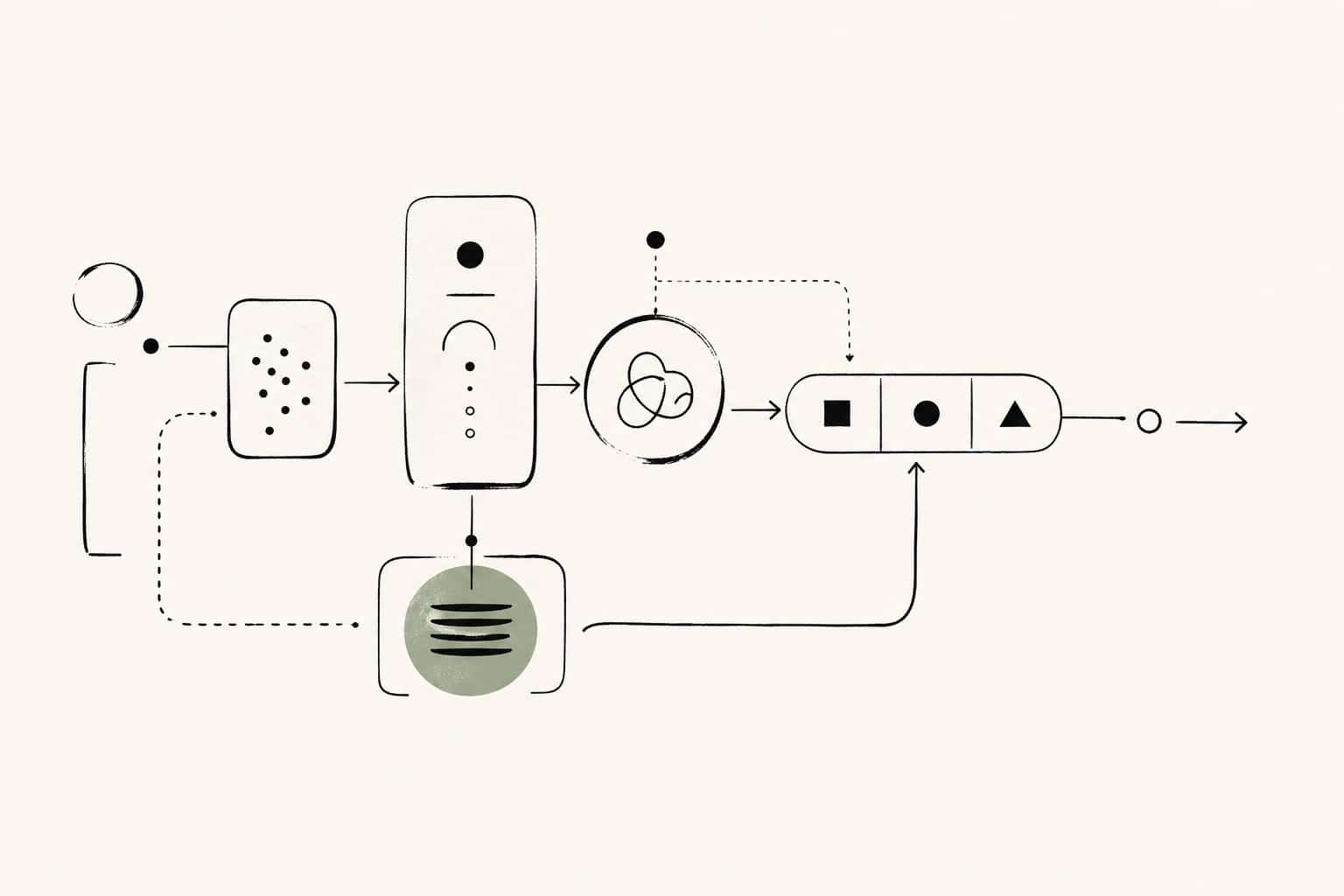
The architecture in one diagram
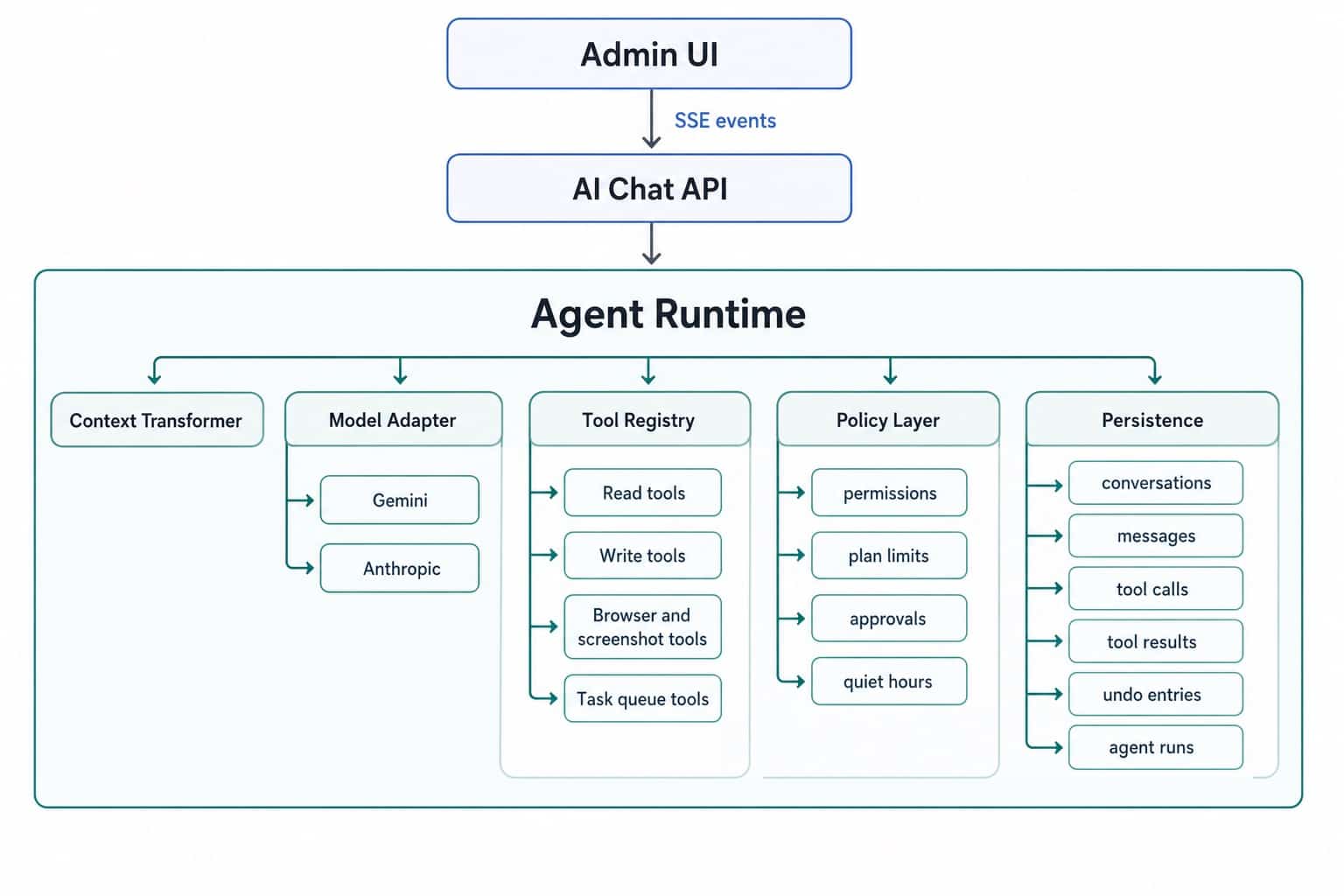
The exact boxes will vary by product. The shape should not.
If your architecture makes it easy to stop a run, inspect a run, resume a run, approve a write, and undo a mistake, you are moving in the right direction. If it only makes it easy to prompt a model and hope for the best, you are still in demo land.
Userorbit
Build agents on top of real product systems, not disconnected prompts
Userorbit gives AI agents structured product context to work with: feedback, announcements, roadmaps, help docs, and release workflows. That makes it easier to build agents that can reason over real state, not just generate text.
- Shared runtime shape for chat, background jobs, and review flows
- Structured product entities that are easier to inspect and persist
- Draft-first workflows for changelogs, help docs, and customer communication
- A foundation for approvals, undo, and safe automation
The takeaway
The biggest mistake teams make is treating agents as prompts plus tools.
That works for demos. It does not work for products.
A production-grade agent is an event-driven runtime. The model plans. The runtime governs. Tools execute through product APIs. State is persisted. Risk is explicit. Users can stop, inspect, approve, and undo.
That architecture is more work up front. It gives you something far more valuable than a chatbot: an agent system that can safely operate inside your product.
References to go deeper
These are some of the systems that have shaped how we think about production-grade agent runtimes:
- Mastra: resumable agent workflows and durable execution patterns
- pi-mono: tool calling and state management
- LangGraph: durable execution, streaming, and human-in-the-loop workflows
- Pydantic AI: production-grade reliability patterns
- OpenHands: local-first agent execution and cloud-scaled multi-agent systems
- Hermes Agent + Userorbit workflows: practical approval-friendly workflows for feedback, roadmaps, and release operations